What are the various ways of
executing a stored procedure in ADO.NET ?
has
four different execute functions :
1. ExecuteScalar ( For scalar queries )
2. ExecuteReader ( For creating a datareader for select query )
3. ExecuteNonQuery ( For Insert ,
Update , Delete )
4. ExecuteXmlReader ( For getting a
XML Reader )
How will you access data from
different Relational and non relational databases?
OLE DB
provides support to access data from different sources. It can connect to
anything.
GUI and
the End Tier doesnt change. Only in your Middle tier
you make changes to acheive the above result.
Generally
code changes will require in the parameters of the function to fetch connection
to Database & the Query may change based on the
database
it access.
What is a View?
Typically
a view is thought of as a virtual table, or a stored query. The results of
using a view are not permanently stored in the database. The data accessed
through a view is actually constructed using standard T-SQL select command and
can come from one to many different base tables or even other views. This T-SQL
select command is stored as a database object (a view). Developers can use the
results from the view by referencing the view name in T-SQL statements the same
way they would reference a real table.
Views can
be updateable in certain situations (only update to 1 of the base tables!).
You can
query views much as you query tables. Modifying data through views is
restricted
Why Indexed Views?
Views have
been available throughout the history of Microsoft SQL Server. However, using
views that return very large result sets can lead to poor performance, as the
result set is not indexed and the entire result must be table scanned if the
view is used in a join or a subquery of a T-SQL
command. Additionally, products like Oracle have come out with the concept of a
Materialized View that give an additional performance boost by being able to
have indexes built on a view. So in the continuing evolution of the SQL Server
product line and in response to Oracle?s
Materialized View, Microsoft SQL Server 2000 has a new feature called the View
Index. View Indexes give the product the capability to define an index on a
view. Additionally, SQL Server View Indexes are dynamic in that changes to the
data in the base tables are automatically reflected in the indexed view. Also
the SQL Server query optimizer will try to use an indexed view even if the view
is not referenced in the from clause of a T-SQL
command. These features are not available in Oracle?s Materialized Views.
View Commands
Like
tables, views have CREATE and DROP commands. (DROP VIEW applies only to the
view, not to the underlying base table.) You access
the data with SELECT statements.
Creating
Views
Here's the
simplified syntax of a view definition statement:
SYNTAX
CREATE
VIEW view_name [(column_name
[, column_name]...)]
AS
SELECT_statement
Follow
your system's rules for identifiers when you name the view.
Specify
view column names if the column is calculated or if multiple columns have the
same name. Otherwise, columns inherit names from the SELECT clause.
Define the
columns and rows of the view in the SELECT statement.
The
following example creates a view that displays the names of authors who live in
SQL
create
view oaklanders (FirstName,
LastName, Book)
as
select
au_fname, au_lname, title
from
authors, titles, titleauthors
where authors.au_id = titleauthors.au_id
and titles.title_id = titleauthors.title_id
and city = '
As you've
seen, the SELECT statement doesn't need to be a simple selection of the rows
and columns of one particular table. You can create a view using any of these
objects or combinations of objects:
A single
table
More than
one table
Another
view
Multiple
views
Combinations
of views and tables
The SELECT
statement can have almost any complexity, using projection and selection to
define the columns and rows you want to include and including GROUP BY and
HAVING clauses. In multiple-object views, you can use joins, subqueries, or combinations of the two to construct
connections in the tables and views underlying the view.
In spite
of the many kinds of views that can be created, there are always limits, varying
from SQL to SQL. Basically, restrictions have two sources:
Elements
not allowed in CREATE VIEW statements (ORDER BY and sometimes
Elements
permitted in CREATE VIEW statements (computed columns, aggregates) that can
limit the data modification permitted through the view because of the problem
of interpreting data modification statements.
The
view-updating problem is explained and illustrated later in this chapter. If
you want users to be able to perform most functions through a view, you may
decide to modify a perfectly legal CREATE VIEW statement to avoid these
limitations.
Displaying
Data Through Views
Creating a
view doesn't produce a display. When SQL receives a CREATE VIEW command, it
does not actually execute the SELECT statement that follows the keyword AS.
Instead, it stores the SELECT statement in the system catalogs.
In order
to see data through the view, query the view, just as you would a table.
SQL
select
*
from oaklanders
FirstName
LastName Book
========= ==========
===============================================
Marjorie Green
The Busy Executive's Database Guide
Stearns MacFeather Cooking with
Computers:
Surreptitious Balance
Sheets
Marjorie Green
You Can Combat Computer Stress!
Dick Straight Straight Talk About Computers
Livia Karsen Computer Phobic and Non-Phobic
Individuals:
Behavior Variations
Stearns MacFeather Computer Phobic and
Non-Phobic Individuals:
[6
rows] Behavior Variations
LastName count(titles.title)
========================================
====================
Green 2
MacFeather 2
[2 rows]
Dropping
Views
The
command for removing views is:
SYNTAX
DROP VIEW view_name
If a view
depends on a table (or on another view) that has been dropped, you won't be
able to use the view. However, if you create a new table (or view) with the
same name to replace the dropped one, you may be able to use the view again, as
long as the columns referenced in the view definition still exist. Check your
system's reference manuals for details.
Diff between StoredProcedure
and UserDefined Functions?
We can get
multiple records set from Stored Procedure. From User Defined functions we can
get maximum one recordset in form of table variable.
Stored
Procedure we can call from middle tier applciation
like VB, ASP. User defined function can only used in T-SQL statements.
User
Defined function we can use as a Table in select statement or in Joins.
One major
difference is that UDFs can be used as part of an
Expression and can be used in SQL Select clause so we cant
use Functions to perform any kind of DML operations
on the table.
Difference between Stored Procedure
and User Defined Function ?
UDF
and STored Procedure
UDF : Excutable from SQL,SELECT and SQL action queries
SP :Use EXECUTE or EXEC to run
UDF : Doesnt return output
parameters
SP : Supports output parameters
UDF : Returns table variable
SP : Can create a physical table and populate it, but cant return a table
variable
UDF : Can join to a UDF
SP : Cant join to a SP
UDF : Cant make permanent changes to the server
environment or an external source
SP : SP can be used to change some of the server environment and operiting environment
UDF :
Cant be used in an XML FOR clause
SP : Can be used in an XML FOR clause
UDF : T-SQL errors stops the function when an error
occurs
SP : Errors are ignored and T-SQL processes the next statement. Error handling
code is to be done manually
UDF :
User CREATE FUNCTION to create
SP : User CREATE PROCEDURE to create
Explain the diff between DBMS and
RDBMS?
DBMS :
a computer program that manages a permanent , self-descriptive repository of
data
RDBMS :
a computer program that provides an abstraction of relational tables to the
user. It provides 3 kinds of functionality 1) present data in the form of table 2) provide
operators for manipulating the tables and 3) support integrity rules on tables.
How do you run SQL statements from
VC++?
By using CDatabase class and using the method ExecuteSQL () you can run SQL Statements
directly from VC++
What is a Trigger?
Trigger
defines an action the database should take when some database-related events
(insert/update/delete) occurs. The code within Trigger called the trigger-body
is made up of PL/SQL blocks. Triggers are executed by Database.
Note: When
enforcing business rules first relay on declarartive
referential integrity Only Use Triggers to enforce those rules that cannot be
coded through referential integrity.
Types of
Triggers is classified based on type of triggering transaction and based on
level at which triggers are executed. They are 1) Row level Triggers (triggers
executed once for each row in a Tx)2)
Statement level Triggers (triggers executed once for each Tx)
3) Before and After
Triggers(inserts/updates/deletes) 4) Instead-of Triggers (redirection
takes place) 5) Schema Triggers (events during create/alter/drop tables) 6) DB
level Triggers (events when errors,
logon, logoff, startup and shutdown). Rather can calling large block of code
within a trigger body you can save the code as a stored procedure and call the
procedure from within the trigger by using a call command
To enable
trigger use -> alter trigger abc
enable;
To enable
all triggers of a table -> alter table abc
enable all triggers;
To disable
triggers -> alter trigger abc disable /alter table
abc disable all triggers
To drop
triggers -> drop trigger abc;
In short -Its an PL/SQL block that fires with DML
command. It is not called explicitly. It is executed automatically when the
associated DML is issued. 2Types -> Row Level and Statement level
Triggers
Example:
CREATE or
REPLACE TRIGGER my_customer_audit BEFORE UPDATE On my_customer FOR EACH ROW
BEGIN
INSERT INTO update_check Values('Updating a row', sysdate);
END;
Explain each:
DDL
-> Create , Alter, Drop, Truncate
DML
-> Insert, Delete, Select, Update ( all have
implicit cursors)
DCL
(Data Control Language) -> Commit, Rollback and SavePoint
View ->its an logical table (not a physical table). You can only
insert / Delete but you cannot update.
What class you in MFC use to
connect to Database? And Connect to Tables? ---------àCDatabase and CRecordSet
Provide a SQL statement to SORT the
records? ------------à ORDER_BY
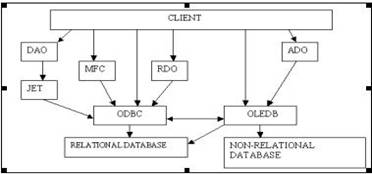
DataBase Arch
ODBC:
provides ODBC driver managers and ODBC drivers. It’s an
low-level API used to interact with DB.
DAO:
provides object model for DB programming. Provides Automation Interfaces, Uses
JET /Access DB Engine
RDO:
developed for VB programmers. Call ODBC API’s directly
OLEDB:
provides Com Interface alone. It doesn’t provide Automation Interface. Used to
access both Relational and Non-Relational databases
MFCODBC:
acts as an wrapper to OBDC
API’s. It’s considered as high-level DB interface.
What is Normalization?
To
eliminate data redundancy, to eleminate inconsistent dependency , actually to speedup your application, to
incorporate the flexibility in the design so as to easily adopt to new changes
What is outer join?
Outer
Joins are almost similar to Inner Joins, but in Outer Joins all the records in
one table are combined with records in the other table even if there is no
corresponding common value.
SELECT * FROM table1 LEFT
OUTER JOIN table2 ON table1.name = table2.name/
What is a Cursor?
When a SQL
statement is executed oracle opens a private workspace area in the system
called Cursor. There are 2 types
Implict
Cursor(all DML
statement uses) Explicit Cursor (only
used by the SELECT statement when
returning multiple records)
What is the Diff between Procedure
and Function?
Both are
PL/SQL named blocks used to perform a specific task .
Only difference is a Procedure may or may not return a value whereas Function
must return a value. Note: Procedures:-Sophisticated Business logic and
application logic can be stored as procedures within oracle. Unlike procedures,
functions can return a value to the caller.
What is an Index table?
Its
based on a sorted ordering of the values. Index table provide fast access time
when searching.
Explain the Levels Normalization
Process?
First Level : Eliminate
repeating of groups of data in each table by creating separate tables for
each group of related data. Identify each set of related data with a primary
key
Second Level : Releate tables
using Foreign key
Third Level : Eliminate fields/columns that do not depend on the
key
Fourth
Level: in many-to- many relationship independent entites cannot be stored in the same table (most developers
ignore this rule)
Fifth Level : the Original
Table must be reconstructed from the tables into which it has been broken down.
Its only useful when dealing with large data schema
Zero Form : If a DB which does not complains to any of the
Normalization forms. This type is usefull only for
data ware housing.
Explain Different KEYS available in
DB?
CANDIDATE
KEY - an
attribute that uniquely identifying a row. There can be more than one candidate
key in a table
PRIMARY
KEY - a Candidate key that you choose to identify rows uniquely is called primary
key. There is only one PK for a given table.
ALTERNATE
KEY -the Candidate keys that was not choosen as
primary key.
COMPOSITE KEY : when a key is made of more than one candidate keys
FOREIGN KEY : used to relate
2 tables using a common attribute. When a primary key in one table is available
as an attribute in another related table is called FK.
Define Entity Integrity
?
It ensures that each row can be uniquely
identified by an attribute called the primary key which cannot be NULL.
Define Referential Integrity ?
It ensures that all the values in the foreign
key matches with the primary key values is called referential integrity
Define ER Diagram
?
It’s a
graphical representation of DB Structure. It has 3 things Entity (Table Name);
Attribute (Column Name); and RelationShip
MTS: - It’s a service available to the
client in the background providing support to Manage
both Component and Tx. It also provides service to
applications that don’t use Tx.
As a service it allocates, activates, deactivates instance of component
that are used by your application. This can improve response time and resource
availability. As a Tx Processor allows to build a reliable and robust data management application
much simpler, especially in distributed application where the data resides on
different / remote servers.
MTS
can be managed using “ Tx
Server Explorer” and in NT we call MMG (Microsoft Management Console)
In WinNT
add reference to “MTS Type Library” to VB Project
whereas in Win2k use “COM+ service type library”.
Explain MTS
Context ?
Component
Creation and Destruction problem is solved by providing a pool of component
instances like connection pooling. MTS can provide a
component to an application on demand and allow other application to use the
same component when the first one is just hanging on to the component instance.
It does this by fooling the application into thinking still it holds a
reference to the component when infact MTS has stealed it away while
application was not looking and given it to someone else. If the first
application suddenly want to use the component then MTS
rushes around the pool and steals one and handle it back to the application. If
it doesn’t find none in the pool it will immediately
create one and handle it back to client. MTS achieves
this by using a context object to the application where the application thinks
this as a real component. But what MTS has given is
just an empty shell.
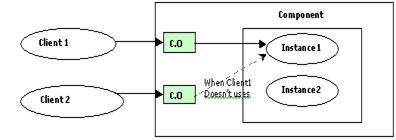
Tx Server
MTS
provides a context for each application wherein the client
don’t realize that the object they are referring are being shuffled
around behind the scenes. Every Context object exposes a COM Interface IobjectContext using which a Tx can be Committed/Aborted/Disabled/Enabled/ Check
Security Issues.
Similarly IobjectControl is used to activate and deactivate the
component. //Even it exposes CanBePooled ()//
Why we need MTS?
We often
need to carryout Tx
operation that spans different Databases, which may be on different servers and
even at different locations. MTS can do this for us automatically.
MTS internally uses DTC
(Distributed Tx Coordinator)
and RM (Resource Manager) to achieve this.
Explain the Tx Supported by MTS?
Req a new Tx :
MTS will start a new Tx
each time on Instance is activated
Req a Tx :
The component will run within an existing Tx if one
already exists. If not MTS will create a new one.
Supports
Tx :
The component will run within an existing Tx if one
already exists. If not will run without a Tx.
Does
not support Tx :
The component will always run outside any existing Tx
Note:
Generally set Req a New Tx
to parent Component while setting Req
a Tx to
child component
Explain ACID property?
Atomicity: -
If all the actions within a Tx either complete successfully or none be
executed at all.
Consistency: -
If all the actions within a Tx
doesn’t break any rules laid for that environment. Meaning Data Integrity
is absorbed.
Isolation: -
If all actions within a Tx
gives the same result when running these actions one at a time serially (one
after another). If results are different then Tx is not isolated
Durable: -
If all the actions within the Tx stores their result
in a permanent device before they report success.
Explain the Types of database read
problems?
Lost updates: When a Tx updating a record, another Tx starts updating the same record before the
first Tx commits or aborts.
Dirty
Reads: When a Tx’s updations
are visible to second Tx before the first Tx commits.
Unrepeatable
Reads: Tx
reads the same record twice and gets different results because inbetween the reads a Second Tx
has updated the record.
Phantom
Read: A Tx reads the same set of record
twice and gets different results because inbetween
the reads a second Tx added a new record or
removed a record from the same table.
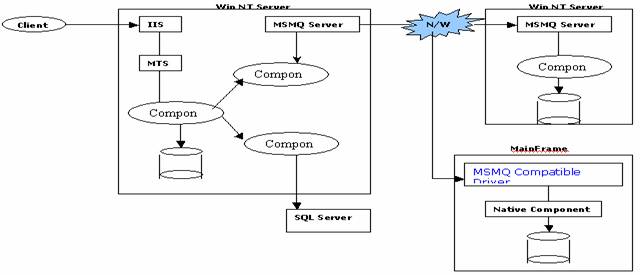
Why MSMQ Series?
Provides
one of the simplest solutions for communication between distributed system in
diff environment and guarantee the delivery of messages even if the system shut
downs.
Adv of DAO
Better performance , Compatibility with ODBC, ability to specify
relationship between tables , provide access to validation rules , support DDL and DML
Note:
DAO works
with 32 bit whereas ODBC works with both 32and 16 bits
DAO does
heterogeneous joints for you, whereas ODBC forces you to do it
DAO
snapshots are read only while ODBC is updatable.
If you are
developing an application that access data from datasource
ranging from mainframe to desktop or if you are building a web application
designed to provide user the datasources then
DDX : used to initialize the controls
entered by user
DDV : used to validate the data entered
by user
RFX:
used to exchange data between database table and recordset
variables
When to use DAO/ ODBC
If you are
planning to work with JET DB then use DAO else use ODBC. Access ODBC via DAO
when you need the speed of JET DB Engine and Extra Functionality of DAO Classes
DeadLock : Its an Execution state for some
set of threads. When each thread in the set is blocked waiting for some action
by one of the other threads in the set , now each is
waiting on the others and none will ever become ready again which causes in a DeadLock.
So a
deadlock is one where 2 threads waiting for each other to release.
This can be avoided by using the foll technique:
1)unlock
the most recently locked objects first
2) ensure that threads lock shared objects in the same order
3) ensure
that a thread which is causing another to wait does not use ::sendmessage()
to send a message to the waiting thread , since sendmessage()
would never return.
RACE CONDITION : occurs when
multiple threads Read and Write to a same memory without proper
synchronization resulting in incorret value being read/ written.The
operating system is responsible for
scheduling and
execution of threads.
What’s the difference between a
primary key and a unique key?
Both primary key and unique enforce uniqueness of the column on
which they are defined. But by default primary key creates a clustered index on
the column, where are unique creates a nonclustered
index by default. Another major difference is that, primary key doesn’t allow NULLs, but unique key allows one NULL only.
How to
find 6th highest salary from Employee table
SELECT TOP
1 salary FROM (SELECT DISTINCT TOP 6 salary FROM employee ORDER BY salary DESC) a ORDER BY salary
What is a join and List different
types of joins.
Joins are
used in queries to explain how different tables are related. Joins also let you
select data from a table depending upon data from another table. Types of
joins: INNER JOINs, OUTER JOINs,
CROSS JOINs. OUTER JOINs
are further classified as LEFT OUTER JOINS, RIGHT OUTER JOINS and FULL OUTER
JOINS.
How can I enforce to use particular
index?
You can
use index hint (index=index_name) after the table
name. SELECT au_lname FROM authors (index=aunmind)
What is sorting and what is the
difference between sorting and clustered indexes?
The ORDER
BY clause sorts query results by one or more columns
up to 8,060 bytes. This will happen by the time when we retrieve data from
database. Clustered indexes physically sorting data, while
inserting/updating the table.
What are the differences between
A join
selects columns from 2 or more tables. A union selects rows
What is the Referential Integrity?
Referential
integrity refers to the consistency that must be maintained between primary and
foreign keys, i.e. every foreign key value must have a corresponding primary
key value
What is the row size in SQL Server
2000?
8060 bytes.
How to determine the service pack
currently installed on SQL Server?
The global
variable @@Version stores the build number of the sqlservr.exe, which is used
to determine the service pack installed.
What is the use of SCOPE_IDENTITY()
function?
Returns
the most recently created identity value for the tables in the current
execution scope
What are the different ways of
moving data/databases between servers and databases in SQL Server?
There are
lots of options available, you have to choose your
option depending upon your requirements. Some of the options you have are:
BACKUP/RESTORE, detaching and attaching databases, replication, DTS, BCP, logshipping,
INSERT...SELECT, SELECT...INTO, creating INSERT scripts to generate data.
How do you transfer data from text
file to database
Using the BCP (Bulk Copy Program) utility.
How do I
import a text file of data into a database?
Well, you can't do it directly...you must use a utility, such as
Oracle's SQL*Loader, or write a program to load the data into the database. A
program to do this would simply go through each record of a text file, break it
up into columns, and do an Insert into the database.
What's the difference between DELETE
TABLE and TRUNCATE TABLE commands?
DELETE
TABLE is a logged operation, so the deletion of each row gets logged in the
transaction log, which makes it slow. TRUNCATE TABLE also deletes all the rows
in a table, but it won't log the deletion of each row, instead it logs the deallocation of the data pages of the table, which makes it
faster. Of course, TRUNCATE TABLE can be rolled back.
What is a deadlock?
Deadlock
is a situation when two processes, each having a lock on one piece of data,
attempt to acquire a lock on the other's piece. Each process would wait
indefinitely for the other to release the lock, unless one of the user
processes is terminated. SQL Server detects deadlocks and terminates one user's
process
What is a LiveLock?
A livelock is one, where a request for an exclusive lock is
repeatedly denied because a series of overlapping shared locks keeps
interfering. SQL Server detects the situation after four denials and refuses
further shared locks. A livelock also occurs when
read transactions monopolize a table or page, forcing a write transaction to
wait indefinitely
What is DTC?
The
Microsoft Distributed Transaction Coordinator (MS DTC)
is a transaction manager that allows client applications to include several
different sources of data in one transaction. MS DTC
coordinates committing the distributed transaction across all the servers
enlisted in the transaction
What is DTS?
Microsoft®
SQL Server™ 2000 Data Transformation Services (DTS) is a set of graphical tools
and programmable objects that lets you extract,
transform, and consolidate data from disparate sources into single or multiple
destinations
What are defaults? Is there a
column to which a default can't be bound?
A default
is a value that will be used by a column, if no value is supplied to that
column while inserting data. IDENTITY columns and timestamp columns can't have
defaults bound to them.
What are the constraints
?
Table
Constraints define rules regarding the values allowed in columns and are the
standard mechanism for enforcing integrity. SQL Server 2000 supports five
classes of constraints. NOT NULL , CHECK, UNIQUE,
PRIMARY KEY, FOREIGN KEY.
Arch of MTS
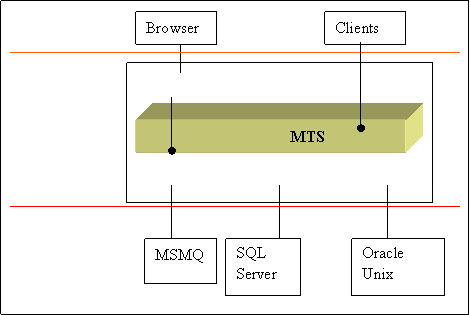
Presentation
Layer
IIS /ASP
DCOM
Application Logic
WinNT
Server
Data and Resources
What is Transaction?
A
transaction is a sequence of operations performed as a single logical unit of
work. A logical unit of work must exhibit four properties, called the ACID
(Atomicity, Consistency, Isolation, and Durability) properties, to qualify as a
transaction.
What is Isolation Level?
An
isolation level determines the degree of isolation of data between concurrent
transactions. The default SQL Server isolation level is Read Committed. A lower
isolation level increases concurrency, but at the expense of data correctness.
Conversely, a higher isolation level ensures that data is correct, but can
affect concurrency negatively. The isolation level required by an application
determines the locking behavior SQL Server uses. SQL-92 defines the following
isolation levels, all of which are supported by SQL Server:
Read
uncommitted (the lowest level where transactions are isolated only enough to
ensure that physically corrupt data is not read).
Read
committed (SQL Server default level).
Repeatable
read.
Serializable (the highest level, where transactions are completely isolated from
one another)
Checkout http://www.intermedia.net/support/sql/sqltut.asp
|
What is an index? What are the types of indexes? How many clustered
indexes can be created on a table? I create a separate index on each column
of a table. what are the advantages and
disadvantages of this approach? |
Indexes in SQL Server are similar to the indexes in books. They help SQL
Server retrieve the data quicker.
Indexes are of two types. Clustered indexes and non-clustered
indexes. When you craete a clustered index on
a table, all the rows in the table are stored in the order of the clustered
index key. So, there can be only one clustered index per table. Non-clustered
indexes have their own storage separate from the table data storage.
Non-clustered indexes are stored as B-tree structures (so do clustered
indexes), with the leaf level nodes having the index key and it's
row locater. The row located could be the RID or the Clustered index key,
depending up on the absence or presence of clustered index on the table.
If you create an index on each column of a table, it improves the query
performance, as the query optimizer can choose from all the existing indexes to
come up with an efficient execution plan. At the same t ime,
data modification operations (such as INSERT, UPDATE, DELETE) will become slow,
as every time data changes in the table, all the indexes need to be updated.
Another disadvantage is that, indexes need disk space, the more indexes you
have, more disk space is used.
|
What are the different
ways of moving data/databases between servers and databases in SQL Server? |
There are lots of options available, you have
to choose your option depending upon your requirements. Some of the options you
have are: BACKUP/RESTORE, dettaching and attaching
databases, replication, DTS, BCP, logshipping,
INSERT...SELECT, SELECT...INTO, creating INSERT scripts to generate data
|
What are cursors?
Explain different types of cursors. What are the disadvantages of cursors?
How can you avoid cursors? |
Cursors allow row-by-row prcessing of the resultsets.
Types of cursors: Static, Dynamic,
Forward-only, Keyset-driven. See books online for
more information.
Disadvantages of cursors: Each time you fetch a row from the cursor, it results
in a network roundtrip, where as a normal SELECT query
makes only one rowundtrip, however large the resultset is. Cursors are also costly because they require
more resources and temporary storage (results in more IO operations). Furthere, there are restrictions on the SELECT statements
that can be used with some types of cursors.
http://www.techexams.net/technotes/mcdba/retrievemodifydata.shtml#116
The SELECT statement, the back-bone of
T-SQL queries, is used to retrieve existing data from a SQL Server
database. The statement retrieves data from the database and presents it back
to the user in one or more result sets. A result set is a tabular
arrangement of the data requested by the SELECT statement. Like any other SQL
Server table, the result set comprises columns and rows. The full syntax of the
SELECT statement is complex and lengthy, but the main clauses can be summarized
in seven parts. Understanding how the SELECT query works is very important. All
other queries are based directly or indirectly on the SELECT query. The
following figure illustrates the main parts of the SELECT statement.
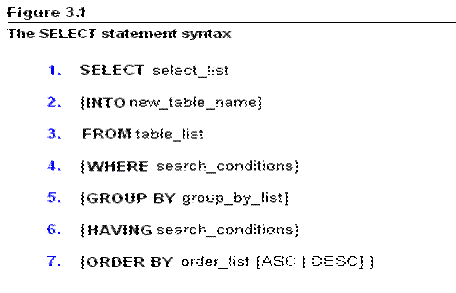
1. The SELECT clause: the SELECT clause is a
required clause and is followed by a select list. A select list describes the
columns of the result set. It’s a column-separated list of expressions. Each
expression points to the source of the data and an alias used as a column title
in the result set (if required). Columns returned in the result set are named
after the column name in the table by default. If you want the columns returned
in the result set to have a different name, you’ll have to define an alias for
the column.
2. The INTO clause: the INTO clause is an
optional clause and is used when you want to create a new table and insert the
resulting rows from the query into it.
3. The FROM clause: the FROM clause is a
required clause and is a comma-separated list of table names, view names, and
join clauses. Use the FROM clause to:
a. List the tables and/or views containing the columns referenced in the select
list. The table or view names can be aliased using the AS clause.
b. Join tables.
4. The WHERE clause: the WHERE clause in an
optional clause and is used as a filter that defines the conditions each row in
the source tables must meet to qualify for the result set. Only rows that meet
the conditions specified in the search_criteria
contribute data to the result set. Data from rows that do not meet the
conditions are not used.
5. The GROUP BY clause: The GROUP BY clause
partitions the result set into groups based on the values in the columns of the
group_by_list. For example, the customers
table contains a State column. Grouping by the state column will partition or
group the results by each customer’s state. This means that customers from
6. The HAVING clause: the HAVING clause is
optional and is used as an additional filter applied to the result set. The
HAVING clause’s filter is applied only after the result set has been passed
through the FROM, WHERE, and GROUP BY clauses.
7. The ORDER BY clause: the ORDER BY clause
is optional and is used to define the order in which the rows in the result set
are sorted. Use the order_list to specify the result
set columns that make up the sort list.
Join
Fundamentals
In the previous sections, we’ve been looking at different ways to query a
single table. There are times when you’ll need information from more than one
table in a single result set. For example, a customers table contains
information about customers. And an orders table includes information about
customer orders. Information in the orders table includes the product ordered,
the quantity and the sales price. You want to know the sales activity of each
customer. Information you want includes the products you sold to the customer,
the total sales price, and of course the customer’s information. Simply put,
the solution to that problem would be to match every customer to his orders and
then add up the sales values and quantities for each customer. It’s possible to
include two tables in the FROM clause without using a Join. But this is how it
looks like.
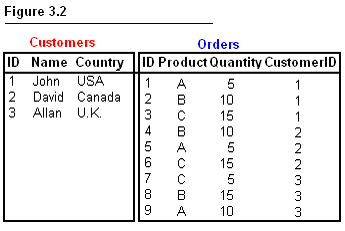
As you can see, the customers table is on its own so is the orders table.
These two tables shown in Figure 3.2 are not related nor matched. You can match
records from the two tables but you’d have to use some complex WHERE clauses
and sub queries.
Matching information in two different tables into one result set is
accomplished by using joins in SQL Server. Look at the following table. Notice
how each order is matched to its customer and vice versa.
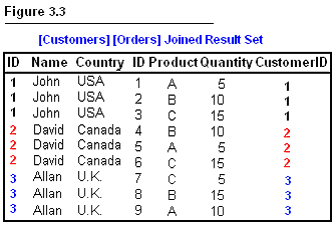
When you
join two tables, you create a logical relationship between them. You can also
specify joining conditions that tables have
to meet in order to qualify in the join. A Join is defined in the FROM clause.
The following is the syntax for Joins.
FROM first_table JOIN_TYPE
second_table [ON (join_condition)]
There are three types of joins in SQL Server; Inner Joins, Outer Joins,
Cross Joins, and Self-Joins. We’ll look at each one at a time.
Inner
Joins
An inner join is a join in which the values in the
columns being joined are compared using a comparison operator. An Inner Join
returns all columns in both tables, and returns only the rows for which there
is an equal value in the join column. In our previous example, we looked at how
the customers and orders table were joined. Let’s take the same example again.
This time, we’ll see how rows that don’t match the join condition are excluded
from the result set.

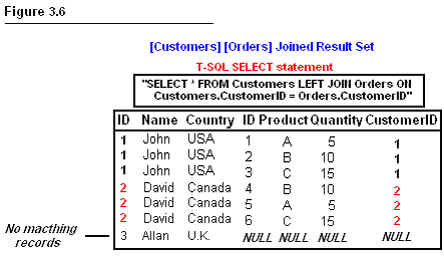
Look at
Figure 3.4, Sam doesn’t have any matching records in the Orders table. This
means that Sam hasn’t placed any orders. If we INNER JOIN these two tables and
define the CustomerID as the join column, rows in the
customers table that don’t have matching rows in the orders table will be
removed and vice versa. The result set will look like this.

Look at
the statement in Figure 3.5. The “JOIN” keyword is assumed to be an “INNER
JOIN” by default. Since Sam (CustomerID:3) didn’t have
any matching records in the orders table, his record in the customers table
didn’t qualify in the joined result set. An Inner Join is some times used to
make a self-join between two instances of the same table. This is done by
joining the table to itself using two aliases. A self join is useful when you
want to find matching values for different rows. An example would be finding
out which employees live in the zip code area as their managers. Since every
employee has a ZIP code column, joining the table to itself would produce the
required result.
Outer Joins
Inner joins return rows only when there is at least one row from both tables
that matches the join condition. Inner joins eliminate the rows that do not
match with a row from the other table. Outer joins, however, return all rows
from at least one of the tables mentioned in the FROM clause, as long as those
rows meet any WHERE or HAVING search conditions. There are three types of Outer
Joins; Left Outer Join, Right Outer Join, and Full Outer Join. Let’s look at
each one at a time.
Left Outer Join
Left Outer Joins retrieves all rows from the left table and only those matching
from the right. When a row in the left table has no matching rows in the right
table, the associated result set row contains null values for all select list
columns coming from the right table. In our previous example, if we defined a
LEFT OUTER join instead of an INNER join, the result set would look like this.
Notice how the orders table columns are filled with the NULL value.
Right
Outer Join
A right outer join is the exact opposite of the left
outer join. It indicates that all rows from the right (second) table are to be
included in the result set, regardless of whether there is matching data in the
left (first) table. When a row in the right table has no matching rows in the
left table, the associated result set row contains null values for all select
list columns coming from the left table. The following is an example of a right
outer join:
SELECT *
FROM Customers RIGHT OUTER JOIN Orders
ON Customers.CustomerID
= Orders.CustomerID
Full Outer Join
To retain
the non-matching information by including non-matching rows in the results of a
join, use a FULL OUTER JOIN. A FULL OUTER JOIN includes all rows from both
tables, regardless of whether or not the other table has a matching value. The
following is an example of a FULL OUTER JOIN.
SELECT *
FROM Customers FULL OUTER JOIN Orders
ON Customers.CustomerID = Orders.CustomerID
Cross
Joins
A cross
join that does not have a WHERE clause produces the Cartesian product of the
tables involved in the join. The size of a Cartesian product result set is the
number of rows in the first table multiplied by the number of rows in the
second table. For example, if the customers table contains 11 rows and the
orders table contains 22 rows, the Cartesian product would be 242 (11 times
22). The following is an example of a cross join.
SELECT *
FROM Customers CROSS JOIN Orders
Cursor
Locking
Let’s take a look at the different types of concurrency problems.
1. Lost Update: Lost updates occur when two or more transactions
select the same row and then update the row based on the value originally
selected. For example, two airline reservation agents retrieve available seats
on a specific flight. Agent1 reserves the seat for customer1. Then agent2
reserves the seat for customer2 thus resulting in a lost update for customer1’s
reservation. This problem can be prevented if a retrieved seat can not be
retrieved again by another agent until the agent either reserves the seat or
cancels the transaction.
2. Uncommitted Dependency (Dirty Read):
Uncommitted dependency occurs when a second transaction selects a row that is
being updated by another transaction. For example, an airline reservation agent
request available seats on a plane. Concurrently, another agent requests
available seats on the same plane. If there was only one available seat, each
reservation agent can inform the customer that a seat is available on the
flight. Now suppose agent1 reserves the seat for customer1 while agent2 and the
customer2 are negotiating on ticket price and other issues. Once customer2 is
ready and agent2 decides to reserve the seat, there is no seat available on the
flight because agent1 has already reserved the seat for customer1.
3. Inconsistent Analysis (Non-repeatable reads):
Inconsistent analysis occurs when a second transaction accesses the same row
several times and reads different data each time. Inconsistent analysis is
similar to uncommitted dependency however, in inconsistent analysis,
the data read by the second transaction was committed by the transaction that
made the change. For example, a travel agency manager wants to know which seat
a specific customer has reserved. Customer1 is currently reserving a seat on a
flight. But because he changes his mind often, he asked for a seat change three
times (seat A, seat B, and seat C). Now suppose the
travel agency manager retrieves the customer’s reservation information after
the customer reserves seat A. The manager uses that information to do other
complimentary services for the customer. Now if the travel agent retrieves the
data again, he ends up with a different seat, seat B. He then bases his data on
this new information, thus rendering his previous read inconsistent or
non-repeatable. This problem can be prevented if the manager reads the
reservations information only after the customer confirms his reservation.
4. Phantom Reads: Phantom reads occur when an insert or delete
action is performed against a row that belongs to a range of rows being read by
a transaction. For example, a travel agency manager requests a customer
reservations report. He then uses that report to give out special offers and
bonuses to frequent customers. Now suppose one customer cancels his
reservation. The report used by the manager is no longer based on true
information. This problem can be prevented if no reservations are cancelled
while the manager is working on his report. An example could be preparing the
report when the travel agent office is closed.
To prevent such concurrency problems from happening, concurrency control
mechanisms must be used. There are two types on concurrency control mechanisms;
Optimistic and Pessimistic.
1. Optimistic Concurrency: Optimistic concurrency
control works on the assumption that resource conflicts between multiple users
are unlikely (but not impossible), and allows transactions to execute without
locking any resources. Only when attempting to change data are resources
checked to determine if any conflicts have occurred. If a conflict occurs, the
application must read the data and attempt the change again.
2. Pessimistic Concurrency: Pessimistic concurrency
control locks resources as they are required, for the duration of a transaction.
Unless deadlocks occur, a transaction is assured of successful completion.
Pessimistic Concurrency control is the default for SQL Server.
Deadlocks
A deadlock occurs when there is a cyclic dependency between two or
more transactions for the same set of resources. For example, transaction1
holds an exclusive lock on the order details table. Transaction1 will not be
committed unless it updates the product quantity in the products. Transaction2,
on the other hand, holds an exclusive lock on the products table. Transaction2
will not be committed unless it updates the quantity information in the order
details table. No transaction can move on thus resulting in a deadlock.
Deadlocks can be prevented in transactions that access the same resources if
they access them in the same order. If transaction1 and transaction2 accessed
the order details and products table in the same order, each transaction would
complete its task and let go of the resource thus allowing the other
transaction to complete.